SaaS startup: How to predict LTV for new users?
When you work in a SaaS startup, you keep asking the same questions over and over:
How to predict and improve LTV?
How to predict when a user will churn?
.
A SaaS product, for Service as a Software, is a web application where users pay a subscription for a service.
Examples are plenty.
It’s a type of business that’s been exploding in the past few years. Think of.
- Dropbox, or Google Drive. Each month, you pay to store data in the cloud.
- Todoist, Evernote, Trello, Focus@Will, Asana, RescueTime, … These services help to improve your productivity. They usually have a free version and a paid one.
- ESP (Email Service Provider), such as Mailchimp, ConvertKit, Drip, etc. You pay each month to manage your email list and send newsletters.
- Dating websites. Creating an account is usually free, but you have to pay to fully use the product.
- Web hosts.
- …
There are so many.
But the questions are the same.
How much money will a new user spend on our product?
That’s LTV, for LifeTime Value. Or CLV, for Customer Lifetime Value.
It’s the value of the user.
Depending on many factors, like the product used, the demographics of the user, his behavior, etc. we predict how much time he’ll stay and how much money he’ll spend.
What is the churn rate?
The churn rate is the proportion of people terminating their subscription after a certain time.
For example, a churn rate of 50% at 3 months means about half of your users cancel the service after 3 months.
It’s a good thing to know your churn rate, but even better to understand what influences it.
What are the most profitable customer segments?
Once you know the LTV, you want to segment your customer base to optimize your sales strategy.
If you realize a certain segment spend way less money and cancel after a month… you could save money by stopping targeting these people.

In this article, we will answer these questions for a SaaS Startup that has 3 years of data on its customers.
Presentation of the SaaS Startup
Of course, we will study a virtual startup.
We have two datasets: customers and subscriptions.
I already cleaned the data, so that in the final dataset, I have:
Three years of data. Between 2015 and 2017. Say we are January 1, 2018, and we want to plan the coming year.
100,000 transactions. More exactly: 96,528 transactions, among 41,971 customers.
One product. SaaS startups usually have many products. We keep things simple and focus only on one. There is no free version, so no conversion rate to predict.
Three predictive variables:
- The acquisition channel: Did the customer come from a Google search or paid ads?
- The device: Is he using his phone or a computer?
- The segment: Shortly after subscribing, the user gets asked whether he’ll use the product for personal or business reasons.
After cleaning and merging, the data, I get:
> data
customer_id first_paid_date channel device segment subscription_id
1: 8010703 2015-01-01 paid unknown other 15202354
2: 8010703 2015-01-01 paid unknown other 17002753
3: 8010703 2015-01-01 paid unknown other 18252044
4: 8010703 2015-01-01 paid unknown other 19502766
5: 8010703 2015-01-01 paid unknown other 23746370
---
96524: 23450765 2017-12-31 paid mobile business 28887609
96525: 23451016 2017-12-31 organic mobile business 28887837
96526: 23451049 2017-12-31 paid mobile other 28887884
96527: 23451058 2017-12-31 paid mobile personal 28887887
96528: 23451104 2017-12-31 paid mobile business 28887955
period_start period_end revenue period_length time churn
1: 2015-01-01 2015-04-01 29.9 3 45 FALSE
2: 2015-04-01 2015-07-01 29.9 3 45 FALSE
3: 2015-07-01 2015-10-01 29.9 3 45 FALSE
4: 2015-10-08 2016-10-08 100.0 12 45 FALSE
5: 2016-10-08 2018-10-08 120.0 24 45 FALSE
---
96524: 2017-12-31 2018-01-31 1.0 1 1 FALSE
96525: 2017-12-31 2018-01-31 1.0 1 1 FALSE
96526: 2017-12-31 2018-01-31 1.0 1 1 FALSE
96527: 2017-12-31 2018-01-31 1.0 1 1 FALSE
96528: 2017-12-31 2018-01-31 1.0 1 1 FALSEThe variables are:
customer_id: Customer IDfirst_paid_date: First subscription datechannel: Acquisition channeldevice: Device (mobile/desktop)segment: Is it for personal or business reasonssubscription_id: Transaction IDperiod_start: Date of the start of the period for this transactionperiod_end: Date of the end of the period for this transactionrevenue: Revenue for this transactionperiod_length: Duration of the period of this transactiontime: Total subscription timechurn: Has the customer churned already?
Note that we are in a very simple case. We have only a handful of predictive variables.
In real life, you would also have:
- More demographics data. Age, location, revenue, all kinds of data the user enters when creating his account.
- Interactions between the customer and the support: You can store all communication (written or spoken) and their frequency. Then, you can even classify them to know whether issues have been solved, whether the client is rather satisfied or not, etc.
- The behavior of the user with the product: Is he using it a lot? Or less and less?
The goal of this article is to keep things simple, and you’ll notice we can already do a lot of things to have a better idea of how the business is operating.
These insights will help the startup to know where to focus its resources.
Churn rate: How to estimate it
First, let’s focus on the churn rate.
We’ll answer questions such as:
- How much time does a customer stay subscribed?
- When does a customer tend to cancel his subscription?
- What are the most impactful variables on churn rate?
To do so, let’s first aggregate the dataset on the customer level:
> data_agg <- unique(data[, .(customer_id, time, churn, channel, device, segment)])
> data_agg
customer_id time churn channel device segment
1: 8010703 45 FALSE paid unknown other
2: 9173798 3 TRUE organic unknown other
3: 9346616 36 FALSE paid unknown other
4: 9650844 27 TRUE paid unknown other
5: 9736636 15 TRUE organic unknown other
---
41967: 23450765 1 FALSE paid mobile business
41968: 23451016 1 FALSE organic mobile business
41969: 23451049 1 FALSE paid mobile other
41970: 23451058 1 FALSE paid mobile personal
41971: 23451104 1 FALSE paid mobile businessThe biased approach
Our first approach will be biased, but this is the most intuitive one.
The idea is to compute the average of the time variable:
> mean(data_agg$time)
[1] 5.190489We could even draw a line of the proportion of customers still subscribed after 1, 2, 3, and more months:
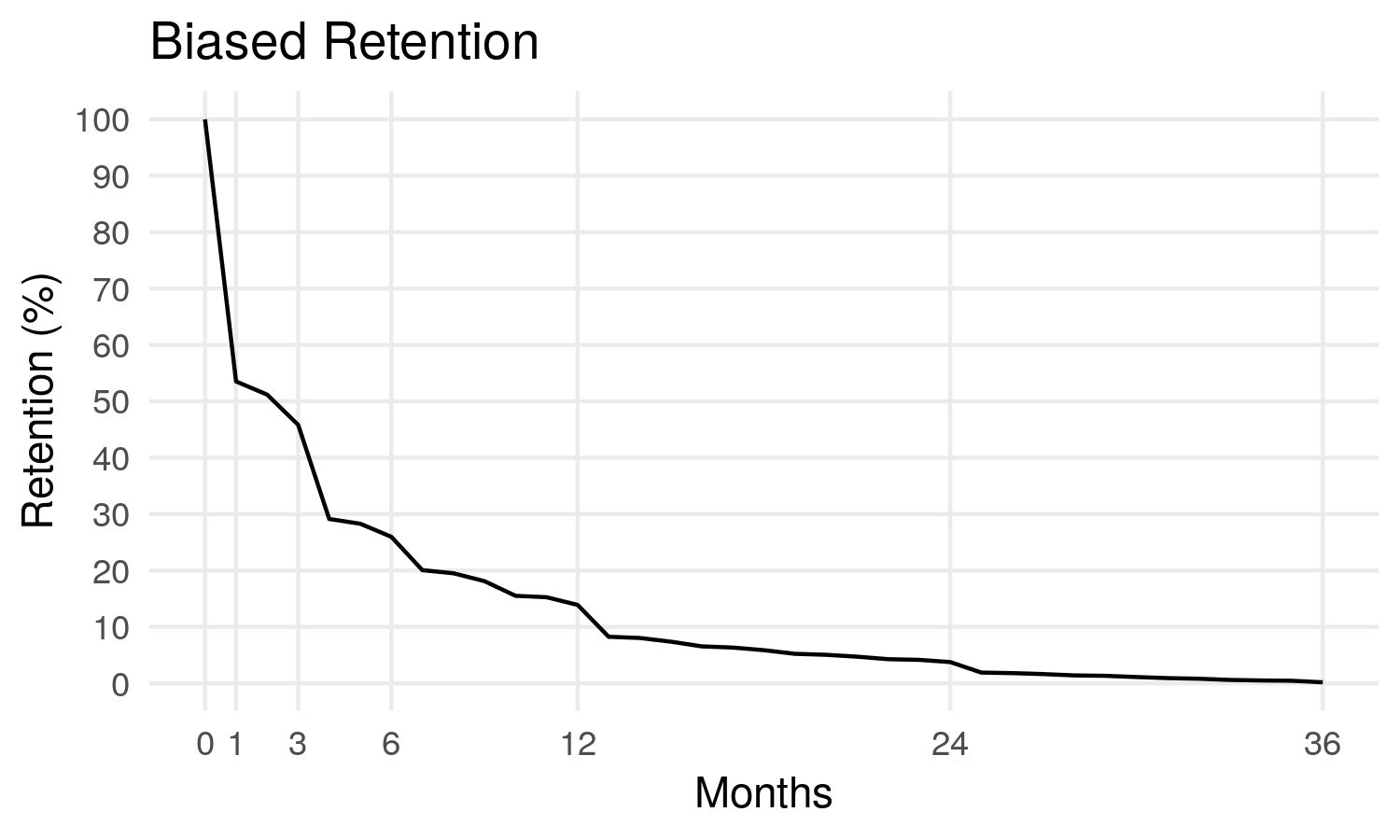
On this chart, we display the retention rate, i.e., we see that after 1 month, we retain a little more than 50% of the initial pool of customers.
After 12 months, we have only 14% of customers left.
Except..
As I was saying, this approach is biased.
Think about it.
In our dataset, we have both churned and non-churned clients, and we consider all of them the same way.
So, when computing our estimate, we actually underestimate the duration of subscriptions for all the customers that haven’t churned yet!
The average and the retention is underestimated too..
What can we do?
The other approach that is not better but worse
Since the non-churned clients are problematic, let’s get rid of them!
No more underestimation!
But..
> mean(data_agg[churn == TRUE, time])
[1] 3.881243We get an even smaller value for the average!
And:
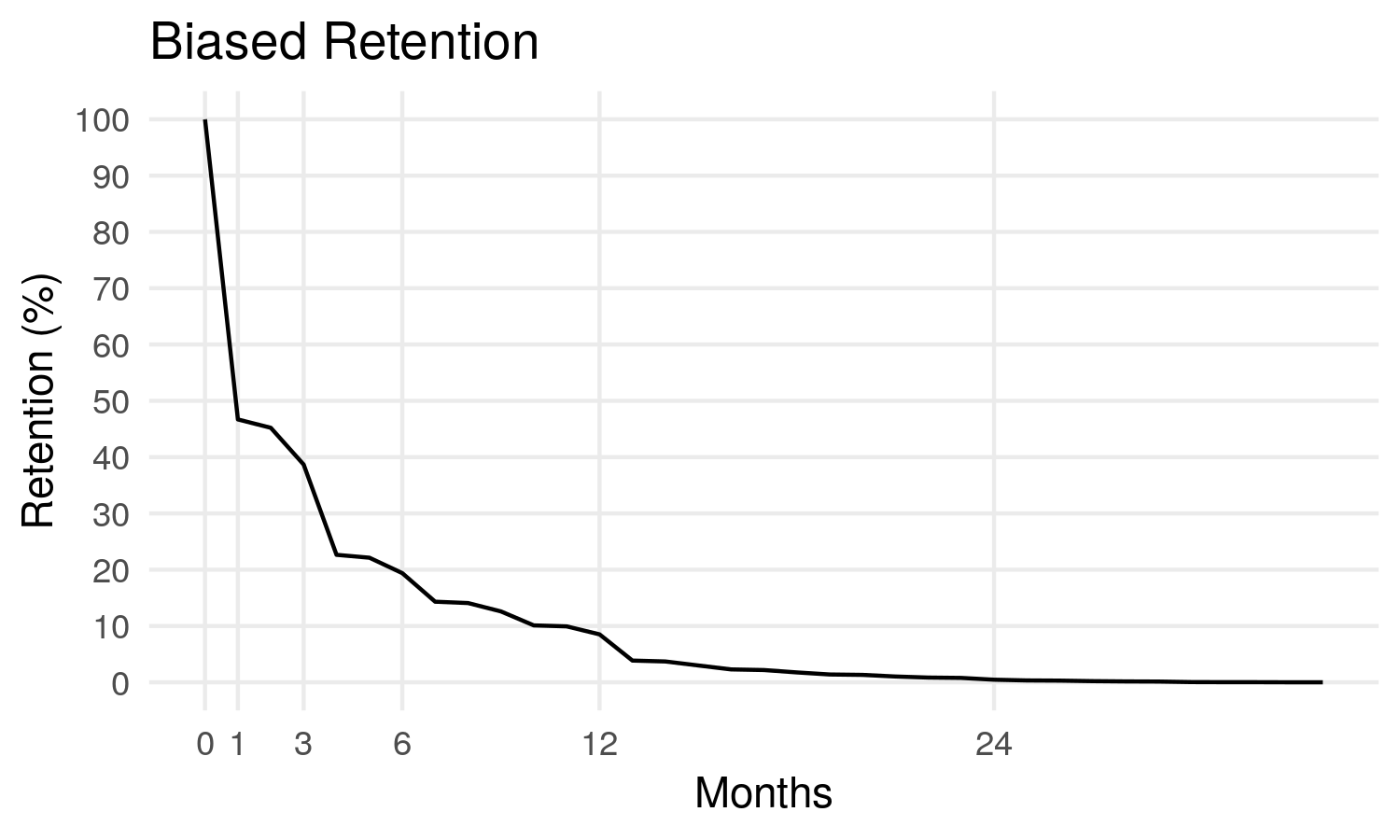
Now, over 50% of customers cancel after a month, and we have only 9% of retention after 12 months.
Weird..
Let’s think.
Actually..
Now that you mention it..
Yea..
We actually removed all the good customers, right?
By removing the non-churned customers, we remove all the ones who tend to stay a long time!
We have an overrepresentation of the bad customers. Those who leave fast.
Oh right!
So.. what to do?
The right approach thanks to Mr Kaplan and Meier
Fortunately, we’re not the first guys with this issue.
Dear Mr Kaplan and Meier have already thought through this.
They even invented an estimator:
It looks like that:
\[\hat{S}(t) = \prod_{i: t_i \leq t}\left(1 - \frac{d_i}{n_i}\right)\]with:
- \(S(t)\) being the survival function. In our context, that’s the retention function. That’s what we’re trying to estimate with the two above charts.
- \(\prod\) is the product symbol. For a certain value of \(t\), we multiply the expression between brackets for each \(i\) when \(t_i\) is smaller than \(t\).
- \(d_i\) is the number of cancellations at time \(t_i\).
- \(n_i\) is the number of remaining customers at time \(t_i\).
If the math is too heavy for you, don’t worry. The goal of this article is not to derive the equations.
I’m showing it here because that looks super serious. But we have functions in R that does the computation for us.
The HUGE benefit of this estimator is that it takes into account that the non-churned subscribers will stay a longer time.
Plus, it’s the maximum likelihood estimator, meaning it has good properties. Especially, it is asymptotically non-biased.
Let’s compare our three estimators now:
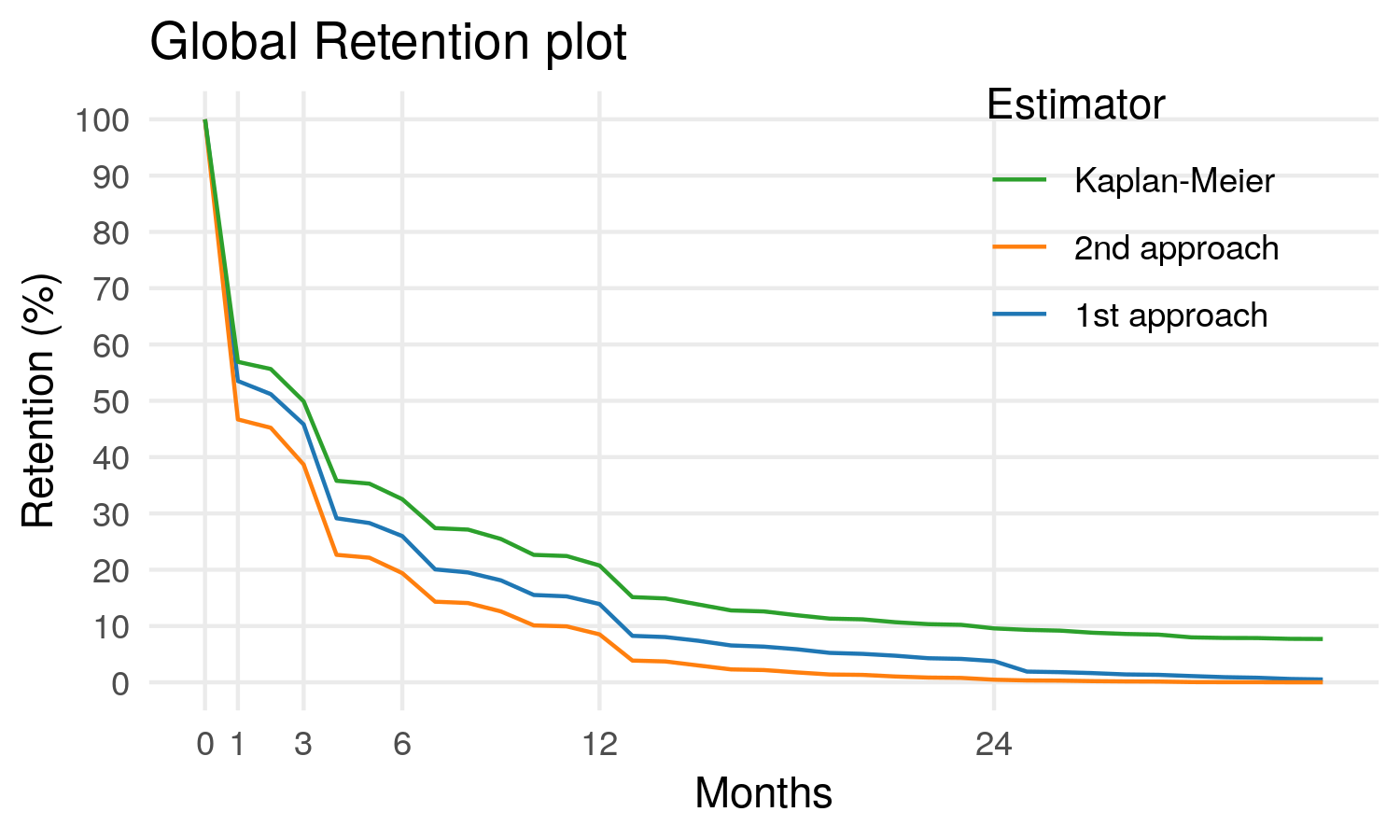
Woah!
That’s a pretty big difference.
Let’s also compute the average:
> sum(data_surv$surv) / 100
[1] 8.243749After 1 month, we have only 43% of users canceling. and after 12 months, 21%.
That’s a huge difference.
But this time, it does take into account users who haven’t churned yet.
Other insightful results
Notice also that:
Median is at 3 months
It means that about 50% of customers will cancel in the first 3 months.
Why?
Is the product too complicated to use for some clients?
Not valuable enough?
Can we maybe identify a specific segment representing these early leavers?
People tend to cancel after…
1 month (43%), 4 months (14%), 7 months (5%), and 13 months (6%).
It can actually be explained easily:
A new user will subscribe only for one month, and if he is satisfied, he will now pay for 3, 6, or 12 months (since it’s cheaper than paying on a monthly basis).
So canceling happens at 1, 4, 7, or 13 months.
It could be a good practice to take a particular care to a customer who approaches these numbers of months.
What’s next?
In this article, we have started to study the retention and churn rate, but we haven’t answered all the questions!
We still have to explain:
- What are the most influencing factors of churn?
- What are the most profitable segments?
- How to estimate the value of a new customer?
- How to estimate the total pool value of our existing customers?
- …
We’ll answer these questions in future articles!
Comments
Ma Yn
Hi, I am doing a academic research over the customer analytics in SaaS company, would you mind if I ask you to share me your data used in this article, pls?
BR,
Ma Yn
Leave a Comment
Required fields are marked *